Abstract
Humans can quickly learn new behaviors by leveraging background world knowledge. In contrast, agents trained with reinforcement learning (RL) typically learn behaviors from scratch. We thus propose a novel approach that uses the vast amounts of general and indexable world knowledge encoded in vision-language models (VLMs) pre-trained on Internet-scale data for embodied RL. We initialize policies with VLMs by using them as promptable representations: embeddings that encode semantic features of visual observations based on the VLM's internal knowledge and reasoning capabilities, as elicited through prompts that provide task context and auxiliary information. We evaluate our approach on visually-complex, long horizon RL tasks in Minecraft and robot navigation in Habitat. We find that our policies trained on embeddings from off-the-shelf, general-purpose VLMs outperform equivalent policies trained on generic, non-promptable image embeddings. We also find our approach outperforms instruction-following methods and performs comparably to domain-specific embeddings. Finally, we show that our approach can use chain-of-thought prompting to produce representations of common-sense semantic reasoning, improving policy performance in novel scenes by 1.5 times.
Approach
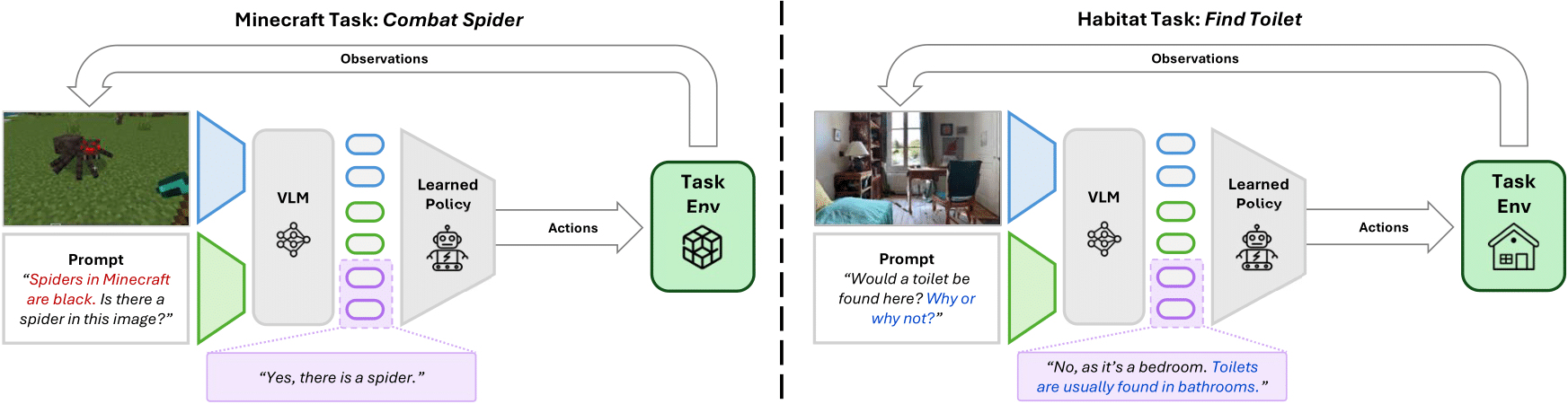
Example instantiations of PR2L for Minecraft and Habitat, showing how the approach can use auxiliary text and chain-of-thought prompting.
Promptable Representations for Reinforcement Learning (PR2L)
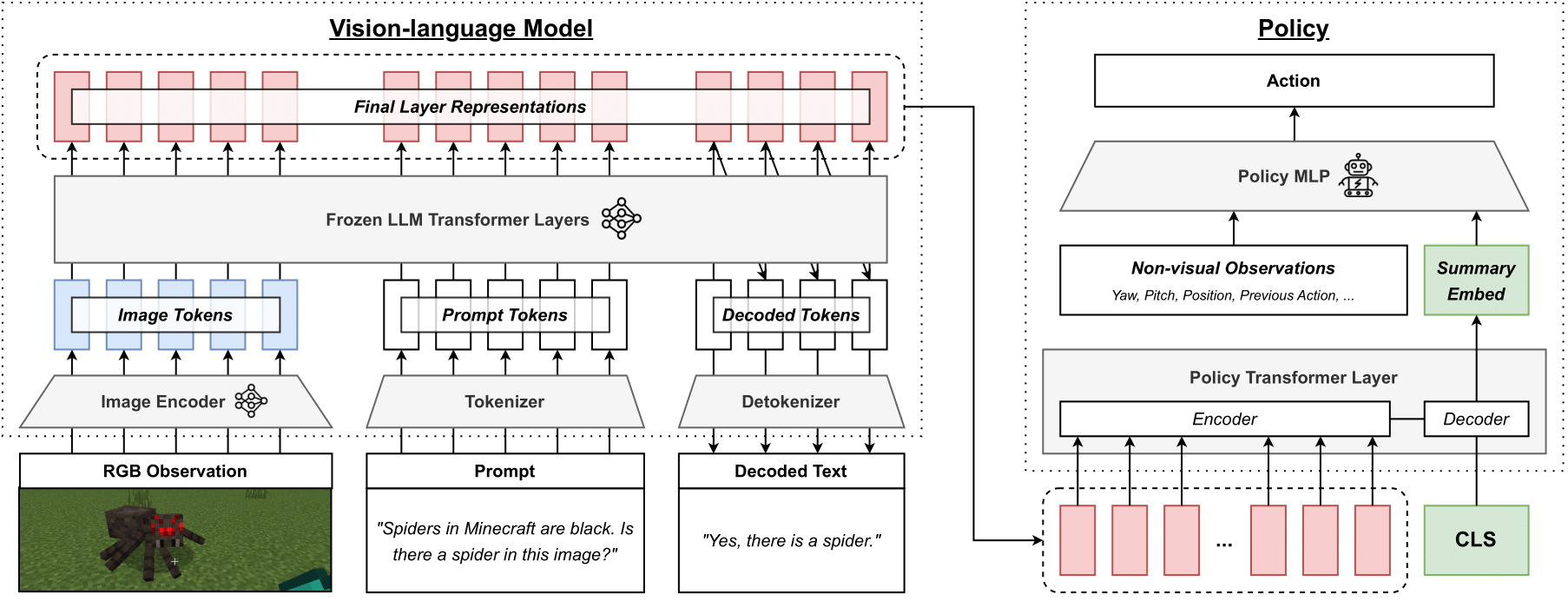
Architecture schematic for extracting VLM representations and using them as the state representations of a learned policy via PR2L.
We initialize policies for embodied control and decision-making tasks with a generative vision-language model (VLM) like InstructBLIP. For each visual observation from the considered task, we pass it into the VLM along with a task-relevant prompt, which encourages the VLM to attend to useful visual features in the image and produce representations that are conducive to learning to execute the task. After the VLM generates text to answer that prompt, the associated promptable representations are given to the policy, which is trained via standard RL algorithms.
Task-Relevant Prompt
Modern VLMs are generally trained to answer questions about images, but often do not know to to produce actions, especially the low-level control signals common to many embodied tasks. It is thus more appropriate to give them questions about the visual contents or semantics of observed images, rather than asking about what actions to take. Doing so produces representations that are grounded in the image, while also allowing for the user to specify specific useful features based on the VLM's semantic knowledge via prompting.
Experiments
Online Reinforcement Learning in Minecraft
We first demonstrate PR2L in online RL experiments in Minecraft. In all cases, the task-relevant prompt asks the VLM to look for and attend to the presence of the task's target entity.
This results in more performant policies than (i) if generic, non-promptable representations are used and (ii) if RT-2-style instruction-following approaches are used.

Behavior Cloning and Offline Reinforcement Learning in Habitat ObjectNav
PR2L also can use chain-of-thought prompting to further draw out relevant task-specific knowledge and shape its yielded representations. We explore this capability via semantic object navigation tasks in the Habitat simulator. We train our policies on a tenth of the Habitat-Web ObjectNav human demonstration data with BC.
We use the prompt "Would a [target object] be found here? Why or why not?" The latter sentence induces chain-of-thought (CoT) reasoning, drawing forth relevant common sense, which the VLM semantically relates to other useful features, beyond just the target object.

While both PR2L policies get higher success rates than all the baselines, using CoT prompting yields the best performance on unseen validation scenes, 1.5 times higher than that of PR2L without CoT. This indicates that PR2L successfully transfers the benefits of VLM common-sense textual reasoning for control, despite said VLM not reasoning about actions.
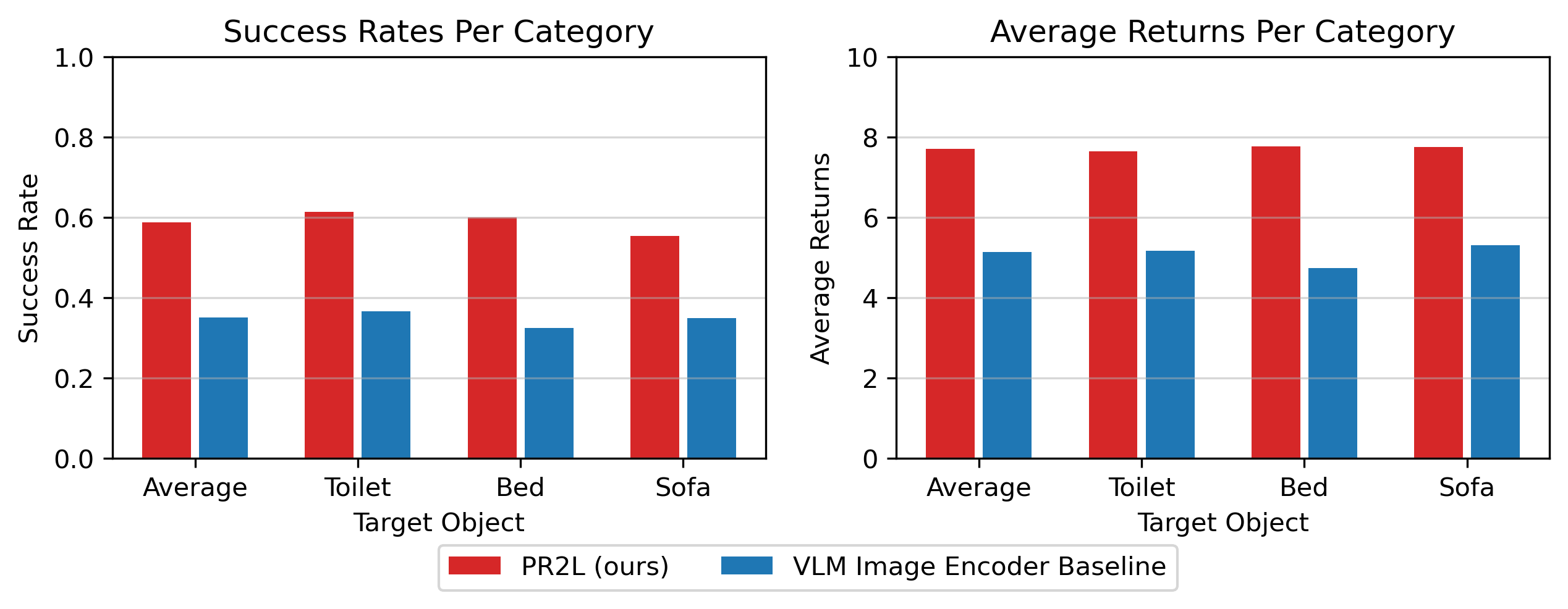
We also conduct offline RL experiments in a simplified version of Habitat, which we use to investigate the sorts of representations yielded by PR2L (as seen in the next section). The prompt shapes the state representation to include the observed room's type, a useful abstraction for finding common household objects.
Analysis of PR2L
To get a sense of why PR2L works, we perform principal component analysis (PCA) of the promptable representations yielded by our VLM and plot each state's first two components. For the Minecraft tasks, we compare PR2L's representations and those yielded by the instruction-following baseline.
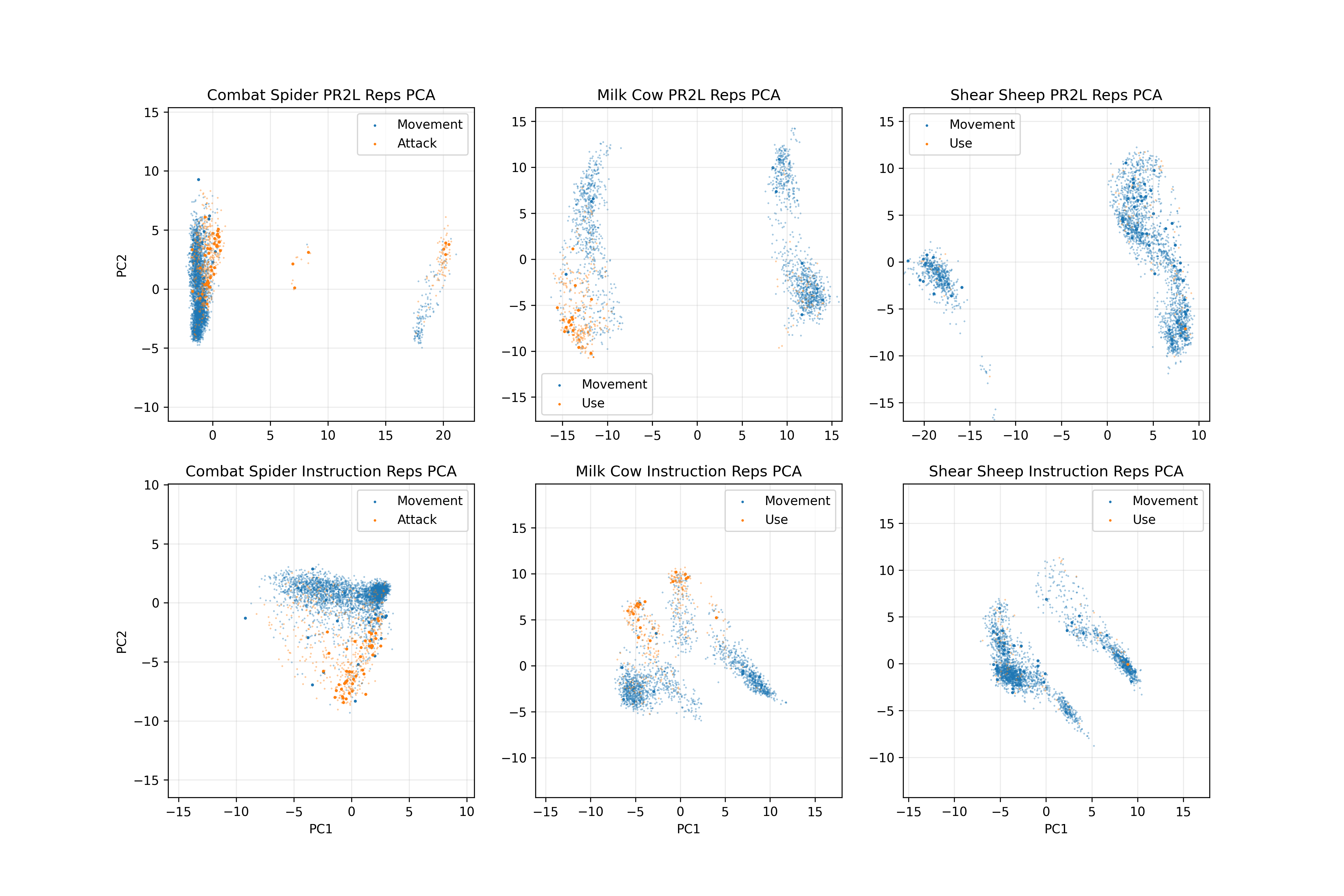
We observe the former yields a distinct bi-modal structure, wherein high-value functional actions (attacking or using items, large orange dots) are clustered together in one mode (corresponding to the VLM saying that the target entity was detected).
We repeat this analysis for the offline Habitat experiments. This visualization is very interpretable, as each cluster corresponds to a different room classification yielded by the VLM. The state's color corresponds to its value under an expert policy (more yellow is higher value).
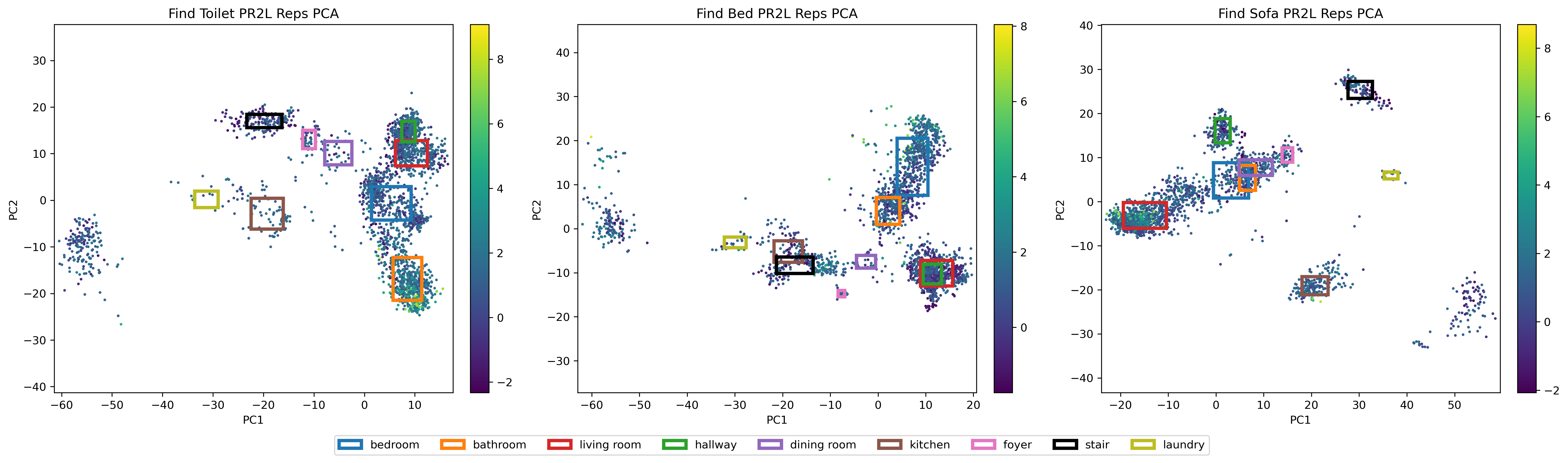
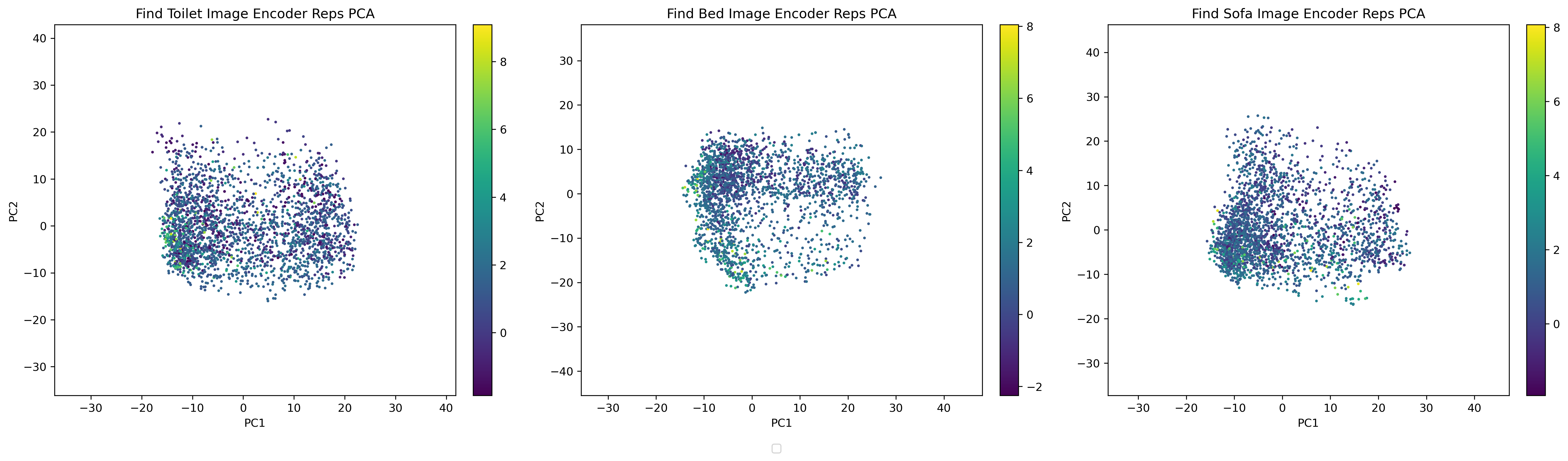
As expected, high value states occur when the VLM's representation captures the room that a target object is expected to be found: toilets in bathrooms, beds in bedrooms, and sofas in living rooms. This structure is absent in the non-promptable image encoder's representations.
Code
We provide a Jupyter Notebook containing an example instantiation of PR2L for a toy contextual bandits image classification problem. To run this example, we recommend running the following commands:
conda create --name pr2l-env python=3.10
conda activate pr2l-env
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=11.8 -c pytorch -c nvidia
pip install transformers
pip install stable-baseline3[extra]
pip install gym ipykernel jupyter
We do not recommend running this on Colab, as the default memory provided (both for the data and for loading the VLM onto a GPU) may be insufficient. We suggest using the code in this notebook as a template for applying PR2L to other domains.
BibTeX
@article{chen2024vision,
title={Vision-Language Models Provide Promptable Representations for Reinforcement Learning},
author={Chen, William and Mees, Oier and Kumar, Aviral and Levine, Sergey},
journal={arXiv preprint arXiv:2402.02651},
year={2024}
}